Data denormalization is broken
Why it’s impossible to write good application-layer code for everyday business logic
Backend engineers can’t write elegant and performant application-layer code for many types of everyday business logic. That’s because no one has yet invented a “denormalization engine”, a database with a more general kind of indexer.
To see what I mean, let’s dive into an example application and talk about its data architecture: how it works today vs. how we’d ideally want it to work.
Example: A messaging application
Say we want to build a messaging application with various conversation “rooms”. Basically a clone of Facebook Messenger, which has one room per person you’re chatting with:

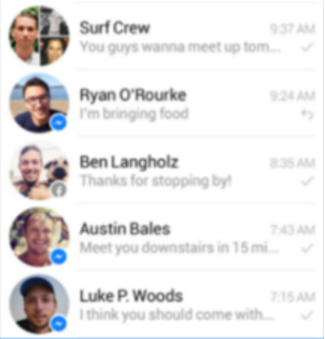
Notice that in this screenshot, there are two unread rooms. We’ll define an unread room (with respect to the current logged-in user) as “a room whose last message’s timestamp is greater than the timestamp when the current user last viewed it”.
Naturally, we want to be able to render a UI like this:
How do we architect the calculation of the number of unread rooms? It seems like a straightforward problem, an example of what I mean by “everyday business logic”.
We’ll consider two architectural approaches for counting unread rooms: the normalized approach and the denormalized approach.
The normalized approach
When building an application, there’s always a core schema of data types and fields that we absolutely need in our database. That’s the normalized schema for our application.
Designing a normalized schema is largely product-definition work, not engineering implementation work. That’s because the set of possible values for the data in a normalized schema corresponds to the set of possible states that your application can meaningfully be in. Good programmers put a lot of thought into designing their application’s normalized schema.
In our messaging app’s normalized schema, there has to be a User type (a.k.a. User table, User collection) and a Room type. There also has to be a Message type, which looks like what you’d expect:
And there has to be a RoomUser type, which stores facts about <roomId, userId> pairs, such as the last time user “liron-shapira” (yours truly) saw the inside of room “r31” (conversation with Sasha Rosse):
Notice that the aforementioned timestamp, 1310 (don’t try to make sense of these fake timestamp numbers), is before Sasha Rosse sent me a message containing the content “Perfect!” This is how the application knows that room r31 is an unread room, and how the UI decides to bold its fonts here:

Similarly, my user saw room r20 at timestamp 1308, which is before Mac Tyler sent me the messages “I have a great idea…” and “Let’s go see Giraffage tonight!” So r20 is a second unread room (with respect to my user):

The other rooms’ RoomUser objects aren’t shown, but we can deduce from their rendered UI’s lack of bold fonts that their corresponding RoomUser.seenTimestamp values are greater than or equal to the greatest timestamp of their contained messages:
The core schema we just went over — whose types include User, Room, Message and RoomUser — is completely normalized, meaning none of the fields are logically redundant with any of the other fields. I define the normalized approach to mean forcing yourself to survive on a completely normalized schema.
In the normalized approach, the number of unread rooms isn’t explicitly stored anywhere in our database—rather, it’s logically implied by the data in our normalized schema. So how do we ultimately make this “2” appear?
The normalized approach’s answer is that we’ll get it from a query, made-to-order at the time we need it. Sounds reasonable, right? Just a little ol’ query. Like this:
HOLY MOTHER, that query has quite a few moving parts, including scans and joins on multiple data types. I wrote it as a ReQL query, but regardless of which database you’re using, its performance is going to be unacceptable at scale. (Ok database ninjas, I’m sure you have a way to configure your query engine to handle this beast, but admit I have a point here.)
And that’s the characteristic problem with the normalized approach: In exchange for the simplicity of working exclusively with normalized data, you have to write queries that don’t scale.
The denormalized approach
The only way we can get efficient queries is to give up on having a completely normalized data model, and add some logically-redundant denormalized fields to our schema.
For our messaging app, let’s add a denormalized field called User.numUnreadRooms. Then a user object will look like this:
This kind of schema is the most efficient thing you could ever hope to query when your frontend needs to show the number of unread rooms:

Query efficiency is a nice-to-have, but if we’re only architecting our messaging app for up to 100,000 users, we can afford to live without it. On the other hand, if we’re architecting for 10M+ users, it’s a must-have. For serving up unread-message counts at scale, the denormalized approach is the only approach.
Let’s keep going with the denormalized approach for our messaging app. So far, all we’ve done is add a field to our schema definition called User.numUnreadRooms. How do we get a value of 2 in there?
The answer is, we need to write an “updater query”, like this:
r.table('user').get('liron-shapira').update({numUnreadRooms: x})That’s part of the answer, but we still have two questions:
- Where in our codebase do we put these kinds of updater queries?
What are all the events that might trigger a modification to a User.numUnreadRooms value? - How are denormalized fields recomputed? In this updater query, what kind of expression is x?
Where do we put denormalization code?
What are all the events in our messaging application for which it might be necessary to update a value of some User.numUnreadRooms field?
Imagine you’re really making this messaging application and try to come up with the answer. Then scroll down…
.
.
.
How about when a new message is sent, and we insert a new Message object into our database? Yep.
How about when a user opens up a room and views its latest messages, thereby updating their RoomUser.seenTimestamp? Yep.
Is that it? Scroll down…
.
.
.
The answer is: there are more situations to think about.
Did you think about what happens if a user leaves or deletes a room, thereby deleting a RoomUser record? (There are other equally valid implementation choices for deleting a room, like setting a Room.isDeleted flag, but I’m picking something compatible with the query-beast from the “normalized approach” section.)
A user who leaves or deletes a room can potentially require you to subtract one from their numUnreadRooms!
How about if you want your messaging application to support deleting individual messages, like Slack does?
If the message being deleted is the only one in the room that a user hasn’t seen yet, then it will need to decrement that user’s numUnreadRooms.
It turns out that quite a few events are tightly coupled with the User.numUnreadRooms field. There’s even one I haven’t mentioned yet. Do you see the potential for buggy code?
It’s not your fault
On the day you’re implementing the User.numUnreadRooms field, you’ll rack your brain for all the places in your code that will need to update it, and I don’t blame you for overlooking the onDeleteRoom event handler.
On the day you’re implementing the onDeleteRoom event handler, you’ll rack your brain for all the denormalized fields that it might need to update, and I don’t blame you for overlooking the User.numUnreadRooms field.
I don’t blame you, the application developer, for any bug in your denormalization logic. I blame the paradigm of tightly coupling denormalization logic with application code.
I’ll talk more about the paradigm shift we need, but first I’d like to keep exploring all the issues with denormalization, and piling on about how annoying they are. And keep in mind, this isn’t supposed to be rocket science. It’s just a messaging application.
How are denormalized fields recomputed?
Say we’re writing some event-handler code for when a user posts a new message, or sees the inside of a room, or deletes a room, or something like that. Recall that the updater query for my liron-shapira user looks something like this:
r.table('user').get('liron-shapira').update({numUnreadRooms: x})There are many ways we can make this updater-query work. The most important distinction is whether we decide to do a pure or an incremental recomputation.
Pure recomputation
If we compute our denormalized User.numUnreadRooms field as a pure function of some of our normalized fields, that’s called a pure recomputation.
Conveniently, the beast-query we were talking about earlier is a pure function of some of our normalized fields. All we have to do is substitute it for x in our updater expression, and now we have an example of pure recomputation:
The nice thing about a pure recomputation is that the new value of User.numUnreadRooms doesn’t depend on the previous values of your denormalized data. If the previous value of User.numUnreadRooms had become corrupted to any extent, or been outright deleted, that’s not a problem.
This is a useful property because it’s pretty common for denormalized fields to get corrupted. You might have a bug in your code which previously calculated the wrong value and stored it. Or the non-atomic semantics of your updater query might occasionally make your value off by one or two (more about atomicity at the end of this post).
Incremental recomputation
Let’s say user sasha-rosse posts a new message into room r31. We know our handler for the “new message” event might need to update my user’s numUnreadRooms, but we’d like to avoid a pure recomputation.
With a pure recomputation, computing resources are wasted scanning indiscriminately through all the rooms I’m in and their message lists, because we know that only one room’s message list is currently being updated. Furthermore, we know that the only possible consequence of a “new message” event for my user’s numUnreadRooms value is either an increment by 1, or no change. We can use this insight to increase the efficiency of our updater logic:
We call this an incremental recomputation of User.numUnreadRooms because it’s not pure — it doesn’t calculate numUnreadRooms as a pure function of other fields’ values. Rather, it introduces a dependency on the previous value of User.numUnreadRooms.
It’s a bit concerning that if our numUnreadRooms value ever gets corrupted or deleted, then no amount of these incremental recomputations will ever get it back to the correct value. We’ve made our denormalized data more brittle. But on the plus side, we got a major performance gain in our updater logic by using an incremental recomputation.
Ok but we didn’t just make our data more brittle; we also made our application logic more brittle. It was hard enough for us to track which event handlers need to run updates on User.numUnreadRooms. Now we also have to invent separate queries for each event handler, with separate clever performance optimizations:

Furthermore, whenever we modify our application’s behavior in any way, we have to reconsider the logic behind each of our incremental recomputations, and whether it still holds sound.
For example, if we introduce a “mark as unread” feature:
Our event handler for “mark as unread” will presumably have its own logic for incrementally recomputing User.numUnreadRooms value, so that’s not the issue. The issue is, do we know whether introducing this new feature will break the incremental-recomputation logic we wrote for the “new message” event handler?
The answer is yes and no:
- Yes: If “mark as unread” works by setting a new normalized-schema field called RoomUser.isMarkedAsUnread to true, then it will break onNewMessage’s incremental recomputation logic. (Can you explain how?)
- No: If “mark as unread” works by setting RoomUser.seenTimestamp to the present, then onNewMessage’s incremental recomputation logic holds sound.
When you modify your normalized schema by adding a field like RoomUser.isMarkedAsUnread, it makes sense that you should have to reconsider the update logic for the User.numUnreadRooms field — but only in one place (like the one beast query in the full-recomputation approach), not throughout your codebase in every event-handler’s logic.
The best compromise
Personally, I bite the bullet and take the denormalization approach in order to make my apps scalable. I hate having to scatter recomputation triggers in an ad-hoc fashion throughout my event handlers, but I don’t see an alternative. It’s a dangerous monster that I have to keep a close eye on.
In order to keep the monster from breaking out of its cage, I stick with pure recomputations wherever I can. If you want to get fancy with incremental recomputation, or you have to because performance is unacceptable, then fine — but you better have some solid tests.
We’re forced to write clunky code
In the last two sections, we saw two reasons why application-layer denormalization is a struggle: we’ve had to struggle to achieve correctness, and struggle again to achieve each incremental improvement in efficiency. After all this struggle, can we at least expect that our efforts will yield good code?
No. It’s the opposite: we can expect that our efforts will yield clunky code.
A good codebase is one that makes you, the programmer, nimble. Such a codebase minimizes your workload in the face of ever-changing (1) behavioral requirements and (2) schema field definitions.
The normalized approach, for all its performance flaws, at least lets us take our beast of a query and wrap it in a function — something like getNumUnreadRooms(userId). That function can be referenced from anywhere in our codebase, so any change to the schema field definition of User.numUnreadRooms requires us to change our code in only one place. With the normalized approach, we are nimble.
But with the denormalized approach, when we change anything about our behavioral requirements or our schema field definition, it breaks our painstakingly-reasoned and painstakingly-optimized code. To fix it, we have to go through our event handlers one by one and re-reason about their correctness and re-optimize their behavior. That’s clunky code.
Denormalization as schema design
If your boss asked you to submit a “schema design” for a messaging app like this, what kinds of information would you include? Probably these three:
- The set of tables (or collections)
- Each table’s fields and their types
- Index definitions
Think about what #3 means. An index definition is a declarative expression that tells a database to create an auxiliary data structure and keep it in sync with one or more of your tables. It’s typically just a few lines of code, but it has a huge impact: it tells your database to crank out nonstop inserts, updates, deletes — any operations necessary to maintain a certain invariant relationship between your tables and that auxiliary data structure.
See where I’m going with this? An indexed field is a special case of a denormalized field! Therefore I propose we give your boss an additional piece of information as part of your schema design submission:
4. Definitions of denormalized fields
If you’re not convinced yet, look what happens when you only write out schema design parts #1 and #2 for the User table (there’s no #3 in this case because we’re not interested in building an index on any User fields):
Is this really worthy of being called a “schema design”? Surely not, because we’re omitting the fact that User.numUnreadRooms is a denormalized field. We’re making it look like an independent degree of freedom that our application state has, which is wrong. So we need to include #4 in our schema design: we need to indicate that User.numUnreadRooms is a denormalized field.
Furthermore, we need to explicitly define an expression that shows how its value is logically determined. What will the actual syntax look like for such an expression? I’m not sure yet. I’m going to think about it more. All I know is that some kind of declarative denormalization syntax is bound to be invented soon, for the same reason index-definition syntax was invented a few decades ago.
A paradigm-shaped hole
It’s obvious to today’s programmers that index definitions should be part of schema design. But at one point it was a paradigm shift. If our databases keep pushing the expressive power of their schema definition languages, we can anticipate that there will be another paradigm shift for database-backed application programming.
In software engineering, a paradigm shift is when something which is bad to think about becomes impossible to think about.
- When you switch from C to a managed-memory language, it’s not bad to think about leaving values lying around on the heap after variables fall out of scope — it’s impossible.
- When you switch from UDP to TCP, it’s not bad to write logic for receiving out-of-order packets — it’s impossible.
- When you switch your DOM rendering code from jQuery to React, it’s not bad to think about mutating client-side state without updating the DOM — it’s impossible.
Right now, working with denormalized data is bad. If you’ve ever written anything less than the perfect denormalized-field recomputation code, then running it will have introduced data corruptions. Just like that, you’ve silently nuked the logical invariant that you were hoping to maintain on your data set. Don’t you wish that were impossible?
Our current approach to denormalization has a paradigm-shaped hole. We can see the outline of a better paradigm ahead; that paradigm just hasn’t been invented yet.
Steps toward denormalization engines
I’m coining the term denormalization engine to refer to a “generalized indexer”: a database engine (or a layer on top) that can process denormalized-field definitions in much the same way as a database can process index definitions.
In our messaging app, User.numUnreadRooms should be a declarative expression in some kind of schema-definition file. We’d like a denormalization engine to understand our definition of that field and always keep it up-to-date for us.
Many databases have taken a few small steps toward being denormalization engines, mostly via their implementations of materialized views (a.k.a. computed indexes).
A materialized view is basically a set of denormalized fields. Many databases force the programmer to manually invoke the recalculation of the values in a denormalized view, but those ones aren’t interesting to talk about here. The interesting ones have either or both of these features:
- Incremental recalculation
Recalculating materialized views incrementally, often by scanning the database’s log from the time the materialized view was last recomputed until the present - Dependency tracking
Automatically detecting when materialized views should be recalculated
The logic of how to infer incremental updates from the database’s log, and the logic of detecting when a recompute is necessary, is nontrivial. So these features represent legitimate steps toward denormalization engines.
Unfortunately, the steps are quite small. The databases that support #1 or #2 don’t claim to do so for arbitrary denormalization relationships. They come with massive restrictions, usually in the form of a whitelist of composable operations.
Oracle’s materialized views seem to offer some of the most advanced functionality out there, but are still very limited. There’s no database in the market today that can implement our desired definition of User.numUnreadFields via a materialized view, as far as I know.
UPDATE: Thanks to Connor McDonald’s reply and others, it seems that Oracle’s materialized views are powerful enough to implement this User.numUnreadFields query.
UPDATE #2: But there’s no database in which it would be practical to have a bunch of material views with arbitrarily-complex queries, and chain such views together in a graph structure.
Building a denormalization engine will be a big technical challenge for the database builders out there. In fact, I used to feel that it was unrealistic to expect that anyone would build a denormalization engine any time soon… until I realized that we’re all currently acting as our own sloppy application-specific denormalization engines, resulting in bugs and clunky code. There’s got to be a way to improve things a little bit beyond the status quo.
Denormalization graphs
We’ve been talking as if denormalized data is a pure function of normalized data. While that’s technically true, it’s often more natural to describe denormalized data as a pure function of other denormalized data.
In our messaging app, it makes sense to define a second denormalized field called Room.lastMessageTimestamp using the following pure function:
Once we have that, we can use it as a building block for a more efficiently-recomputable definition of User.numUnreadRooms:
Once you define denormalized fields in terms of other denormalized fields, you might get a pretty rich directed acyclic graph (DAG) structure which I call a denormalization graph.
When someone invents a way to declare denormalized fields as part of a formal schema definition, all of those field definitions together with your normalized fields should be visualizable on a single denormalization graph.
Event sourcing
Event sourcing means recording all updates to your database with a series of event objects, and being able to recompute all your tables/collections/views as a pure function of your event objects.
(Technically, any database with a log is an example of event sourcing, because we can consider every log entry as an event object. Event sourcing gets more interesting when all your event objects have application-level meaning.)
I just want to put event sourcing on the conceptual radar because if we take the idea of denormalization graphs to the logical extreme, then the only data that can be said to be “normalized data” is precisely that which the event sourcing crowd would call “event objects”.
Event sourcing has a ton of great benefits. This video does a good job explaining some of them. I think the reason event sourcing hasn’t caught on is because there’s no good denormalization engine that can transform our stream of event objects into the schemas we usually consider to be “normalized”.
Atomicity
Many databases don’t support atomic operations, a.k.a. transactions, across different data types. It’s hard to make those scale. That’s surely one of the challenges of implementing a denormalization engine. And that’s why, sadly, none of the updater queries given in this post are atomic.
But this whole post is about a problem that’s strictly easier than atomicity: how to write elegant code that’s correct (ignoring atomicity-violation-caused incorrectness), and reasonably performant, and nimble to change.
I mentioned that I think the best way to operate in today’s pre-denormalization-engine era is to take the denormalized approach, and then stick to pure recomputations only. A pure recomputation is an idempotent operation, meaning you can do it arbitrarily many times without breaking anything. So I figure, if 0.1% of the time the value of some denormalized field is off by one or two due to the lack of atomicity, we’ll just make sure it gets recalculated again sometime soon and the error will go away.
I would love to have a discussion about atomicity guarantees in light of our new shared language about normalized vs. denormalized fields, full vs. partial recomputation, denormalization graphs, etc. But I feel that talking about these things now would be analogous to talking about what HTTP should look like before we’d figured out TCP. The discussion would tend to keep veering into details about how to handle dropped packets, and packets arriving out of order. Let’s focus on building one abstraction layer at a time.
Conclusion
It’s a joy to be able to build full-stack applications from zero to 1.0 in a few days. I personally feel comfortable with 90% of the work required to do so, but data denormalization is still in that last 10% .
I think the database, or the “data layer”, is overdue for a paradigm shift in the way it handles denormalization. I predict that powerful denormalization engines will be invented in the next few years.
In the meantime, I’m planning to give this topic more thought and maybe even hack together a simple proof-of-concept denormalization engine. If you think you’d be interested to throw around ideas or work together, let’s chat.
UPDATE Dec 2016:
I’ve come to think that the framework-level solution to data denormalization has to look something like logic programming. That’s what got me excited about a new programming language called Eve. I just wrote this VI-part post series about Eve, and parts II and VI are basically followups to this post.
UPDATE May 2020:
The Eve project shut down in 2017, and the data denormalization problem continued to sit there unsolved. Software engineers worldwide continue to waste $trillions of person-hours on incidental complexity that can be fundamentally attributed to the lack of declarative data denormalization. Now, finally, there’s a startup who is tackling the problem head on: Materialize. I’m extremely excited about the potential of their technology. And one of their founders was inspired by this post!
